

Benchmarks



AIDA64 includes several benchmarks which can be used to measure the performance of individual hardware parts or the system as a whole These are synthetic benchmarks, which means that they can be used to measure the theoretical maximum performance of the system. Memory bandwidth, CPU and FPU benchmarks are built on the multi-threaded AIDA64 benchmark engine that – since AIDA64 Business v4.00 – supports up to 640 simultaneous processing threads and 10 processor groups. The engine offers full support for multi-processor (SMP), multi-core and HyperTheading technologies.
Cache and disk benchmarks
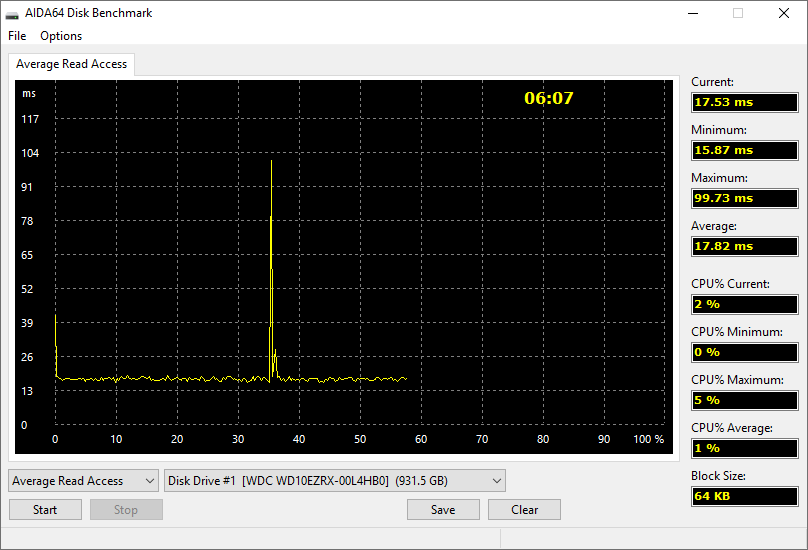
AIDA64 includes dedicated benchmarks for measuring the read, write and copy bandwidth as well as the latency of the CPU caches and the system memory. It also has a dedicated benchmark module for measuring the performance of storage devices, including (S)ATA or SCSI, hard disk drives, RAID arrays, optical drives, solid-state drives (SSD), USB drives and memory cards.
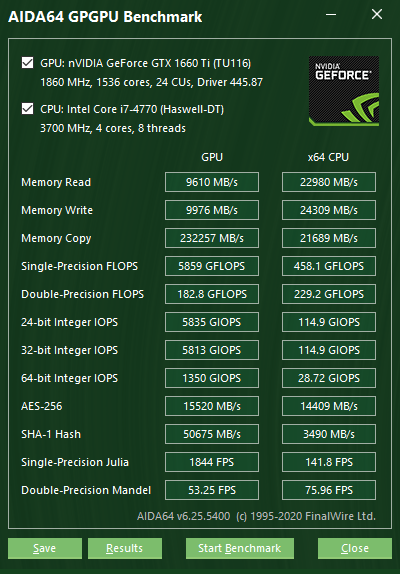
GPGPU benchmark
This benchmark panel, which can be launched from Tools | GPGPU Benchmark, offers a set of OpenCL GPGPU benchmarks. These are designed to measure GPGPU computing performance using various OpenCL workloads. Each individual benchmark can be run on up to 16 GPUs, including AMD, Intel and NVIDIA GPUs, or the combination of these. Of course, CrossFire and SLI configurations as well as both dGPUs and APUs are fully supported. Basically, any computing device that is listed as a GPU among the OpenCL devices can be benchmarked here.
Besides these comprehensive benchmarks, AIDA64 offers dedicated microbenchmarks, which are available under the Benchmark category in the Page menu. Thanks to AIDA64's huge reference result database, benchmark results can be compared to those of other configurations. Currently, the following microbenchmarks are available:
Memory benchmarks
Memory benchmarks measure the maximum bandwidth achievable when performing the selected operations (read, write, copy). These are written in Assembly and they are fully optimized for popular AMD, Intel and VIA processor cores by using the appropriate x86/x64, x87, MMX, MMX+, 3DNow!, SSE, SSE2, SSE4.1, AVX and AVX2 instruction set extensions.
The memory latency benchmark measures the typical memory-to-CPU delay. Memory latency means the time it takes for data to arrive in the integer registers of the CPU after the issue of the read command.
CPU Queen

This simple integer benchmark focuses on the CPU's branch prediction capabilities and branch misprediction penalties. It calculates solutions for the classic “N queens puzzle” on a 10x10 chessboard. In theory, at the same clock speed the processor with the shorter pipeline and smaller misprediction penalties will attain higher benchmark scores. For example, with HyperThreading disabled, Intel Northwood based Pentium 4 processors attain higher scores than Intel Prescott CPUs as the former has a 20-stage pipeline, whereas the latter has a 31-stage pipeline. CPU Queen uses integer MMX, SSE2 and SSSE3 optimizations.
CPU PhotoWorxx

This integer benchmark measures CPU performance with several 2D photo processing algorithms. It performs the following tasks on a very large RGB image:
- Fill the image with random colored pixels
- Rotate 90 degrees CCW
- Rotate 180 degrees
- Difference
- Color space conversion (used e.g. during JPEG conversion)
The test mainly stresses the SIMD integer arithmetic execution units of the CPU as well as the memory subsystem. CPU PhotoWorxx test uses the appropriate x87, MMX, MMX+, 3DNow!, 3DNow!+, SSE, SSE2, SSSE3, SSE4.1, SSE4A, AVX, AVX2 and XOP instruction set extensions and it is NUMA, HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
CPU ZLib
This integer benchmark measures combined CPU and memory subsystem performance using the public ZLib compression library. CPU ZLib uses only the basic x86 instructions, while it is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
CPU AES
This integer benchmark measures CPU performance using AES (Advanced Encryption Standard) data encryption. In cryptography, AES is a symmetric-key encryption standard, which is used in several compression tools today, such as 7z, RAR, WinZip, and also in disk encryption solutions like BitLocker, FileVault (Mac OS X), TrueCrypt. CPU AES uses the appropriate x86, MMX and SSE4.1 instructions, and it is hardware accelerated on VIA C3, VIA C7, VIA Nano and VIA QuadCore processors with VIA PadLock Security Engine; and on Intel AES-NI capable processors. The benchmark is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
CPU Hash
This integer benchmark measures CPU performance using the SHA1 hashing algorithm as defined in the Federal Information Processing Standards Publication 180-4. The code behind this benchmark method is written in Assembly, and it is optimized for popular AMD, Intel and VIA processors by utilizing the appropriate MMX, MMX+/SSE, SSE2, SSSE3, AVX, AVX2, XOP, BMI, and BMI2 instruction set extensions. CPU Hash benchmark is hardware accelerated on VIA C7, Nano and QuadCore processors with VIA PadLock Security Engine.
FPU VP8
This benchmark measures video compression performance using version 1.1.0 of the Google VP8 (WebM) video codec. It encodes 1280x720 pixel (“HD ready”) video frames in 1-pass mode at 8192 kbps bitrate with best quality settings. The content of the frames are generated by the FPU Julia fractal module. The code behind this benchmark method utilizes the appropriate MMX, SSE2, SSSE3 or SSE4.1 instruction set extensions, and it is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
FPU Julia

This benchmark measures the single precision (or 32-bit) floating-point performance through the computation of several “Julia” fractal frames. The code behind this benchmark is written in Assembly, and it is fully optimized for popular AMD, Intel and VIA processors by utilizing the appropriate x87, 3DNow!, 3DNow!+, SSE, AVX, AVX2, FMA, and FMA4 instruction set extensions. FPU Julia is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
FPU Mandel

This benchmark measures the double precision (or 64-bit) floating-point performance through the computation of several “Mandelbrot” fractal frames. The code behind this benchmark is written in Assembly, and it is fully optimized for popular AMD, Intel and VIA processors by utilizing the appropriate x87, SSE2, AVX, AVX2, FMA, and FMA4 instruction set extensions. FPU Mandel is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.
FPU SinJulia

This benchmark measures the extended precision (or 80-bit) floating-point performance through the computation of a single frame of a modified “Julia” fractal. The code behind this benchmark is written in Assembly, and it is fully optimized for popular AMD, Intel and VIA processors by utilizing trigonometric and exponential x87 instructions. FPU SinJulia is HyperThreading, multi-processor (SMP) and multi-core (CMP) aware.